This is an article about a new file format for creating resource bundles for the web. If you want to jump directly to the repository and start using it yourself you can visit the Javascript Binary Bundles Github page.
The problem
The speed of broadband connectivity is ever growing, and with a great speed, comes great lust! Hundreds of new web applications are coming out every day, each one with better and more demanding visuals than their predecessors. But most importantly, the third dimension is now a well-established and widely used technology for the web. Libraries such as three.js makes it easy to manipulate complex, realistic 3D graphics in real-time. However I am not sure if web is fully compatible with it yet. But let me elaborate...
An average 3D project requires dozens of assets, that have to be loaded by the application: meshes, materials, textures, shaders, sounds, scripts etc. Of course, like any other web application, these have to be streamed over the network to the browser. But since very few of them actually provide a streaming content (ex. jpeg images), the application will have to block until all the assets are loaded. For big projects, the loading time can be considerable, not due to the size of the asset, but due to the number of the requests that needs to be performed. Moreover, if you try to be smart and keep the streaming assets for the end, you will end-up with a 3D world with flickering textures until everything is loaded - again, not very user friendly. So an obvious optimization would be to bundle them together, right?
Having a look on the existing loaders and file formats, we can see a plethora of solutions, such as the smart webgl-loader (or UTF8 loader) for Google Body, for loading big meshes, or the the Sea3D toolkit, and finally all the classic formats from the desktop games and applications (MD2, OBJ, 3DS, etc.). All of them try to solve a particular problem (ex. loading meshes), but none of them solves the bundling problem. And even when some special formats do, they are not optimized for the browser. So I thought it's time to roll up my sleeves and get to work!
Towards a Bundling Format
One of the first problems that I wanted to solve is how to organize the resources in bundles. One could think that since the application assets are semantically linked to each other, they can be grouped in bundles. For example, a usual 3D object is composed of it's geometry (the mesh) and it's material (the material description, the shader and possibly textures). However, what happens when thousand different geometries are sharing the same material? Repeating the material on every bundle would be big loss of space. Therefore, the next logical solution is to group assets of same/relevant type together, and allow cross-referencing of bundle contents. For instance, you can have the materials in a separate bundle, the meshes in another, the game objects in a third one etc.
With this in mind, I started to identify the primitives of my new bundle format. In order to explain my reasoning, let's say that we want to bundle the resources to create this simple scene with a spinning, textured cube, like this example from three.js, also seen below:
Breaking down the objects that compose this THREE.Scene we identify the following three.js objects:
- A THREE.Mesh, composed of
- A THREE.BoxGeometry and
- A THREE.MeshBasicMaterial, which is further composed of
- A THREE.Texture, that refers to
- A DOMImageElement that contains the diffuse map
The information for the mesh, geometry and material were provided through the main .js file, and the image was loaded by the browser. Not much of a loading here, but let's try to strip the scene to the bare minimum bytes required to accurately represent it:
- The THREE.BoxGeometry is constructed with a known set of arguments, namely: width, height, depth, widthSegments, heightSegments, depthSegments. Therefore, assuming that the values are small enough, the arguments can fit on 6 bytes, plus 1 byte to identify the class = 7 bytes total.
- The THREE.Mesh is constructed with a reference to a geometry and a material. Assuming that we are keeping a 16-bit long lookup table, the arguments can fit on 4 bytes + 1 byte to identify the class = 5 bytes total.
- The DOMImageElement is required to be available by the time the bundle is loaded, therefore we are embedding it's contents of the image as a blob of binary data. Here we cannot optimize anything further.
Continuing like this, we identify a finite set of primitives:
- JavaScript Primitives (Undefined, Null, NaN, Boolean)
- Numbers
- Objects (Class Instances, or Plain)
- Arrays (Including TypedArrays)
- Blobs (Strings, Images, Scripts or other external resources)
- Internal and External References
As you can see, they happen to be very close to the JavaScript language itself, so a serialization of the scene object should be enough! Unfortunately, as far as I know there is no proper serialization support in JavaScript, and I didn't want to mess with JSON hacks. Therefore I had to come-up with a new, efficient serialization mechanism.
Creating a JavaScript Serializer
The optimization goals for the serialization format were the deserialization speed and the overall bundle size. Of course it was difficult to achieve both of them, therefore I tried to keep a balance, favoring the speed when needed. Also, by those two constraints it became apparent that a binary format would be the most efficient.
Having a look on the binary support in JavaScript, we see that TypedArrays is the way to go. And quite frankly, they provide all the nice primitives that we will be operating upon (U/INT8, U/INT16, U/INT32 and FLOAT64). From the optimization perspective though, there are two issues:
- EcmaScript 6 Provides the very nice DataView class for low-level operations over a typed array. Unfortunately, it seems to perform quite bad compared to other means of data accessing.
- But, if we are going to use TypedArray Views, we have a problem in data alignment. This means that when we are compiling the bundle and we suddenly want to encode a data type other than U/INT8, we need to account the offset and insert the appropriate padding. Just by saying this, you can realize the amount of padding junk that will appear in the file.
Therefore, I decided to use TypedArray views for performance, and to solve the alignment problems by laying out my data structures like so:
| Offset | Region |
|---|---|
| 0x0000 | Header (see below) |
| 0x0018 | 64-Bit Elements (Float64) |
| ... | 32-Bit Elements (Float32, Int32, UInt32) |
| ... | 16-Bit Elements (Int16, UInt16) |
| ... | 8-Bit Elements (Int8, UInt8) |
| ... | Strings (NULL Terminated) |
Therefore, I only need a few padding bytes between the data types!
Having this clarified, I started to work on the format op-codes and how can I pack as many information in small space. Soon, the following requirements became apparent:
- All op-codes must occupy the smallest space possible, at rare occasions they are allowed to extend to more than 1-byte. Therefore, I paid special attention on packing all the information I need in just that byte.
- JavaScript is not strong-typed. Therefore I don't know how wide the number will be. Having a fixed-size numerical type is wrong, therefore I decided to use variable-sized numerals. I also managed to squeeze the type information in 2-bit or 3-bit in worst cases.
- The Arrays in JavaScript are proven to be VERY important. They are frequently encountered, and other primitives (such as objects) can also be represented as arrays. Therefore, I spend an extra effort on array optimization.
That said, here is the op-code table for the primitives:
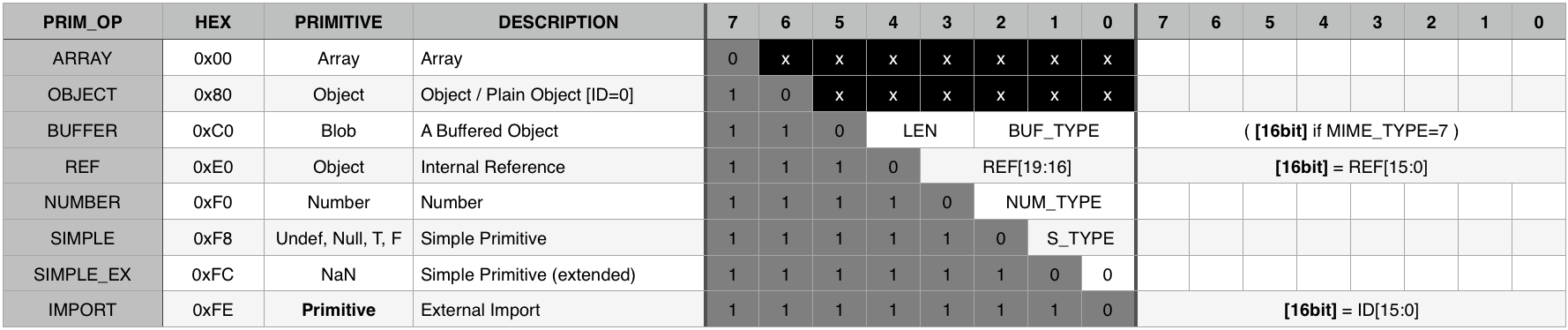
Optimising the Arrays
As mentioned, Arrays are very frequent in JavaScript - Especially in the world of 3D graphics. They usually carry a lot of information and if stored improperly, even this small example can easily occupy a Mb of data (been there). Therefore I decided to spend an additional effort on optimizing them.
I realized that the big majority of arrays in 3D graphics are TypedArrays. So, like any other series of numbers, I could use one of the following:
- Delta Encoding (a cool idea borrowed from the UTF8 mesh encoding)
is used when the values in the array have a small difference (delta)
between them. In this case, they are encoded as an array of smaller type, containing the differences betwen them. For instance a
INT32array can be encoded asINT16or evenINT8if the differences are small enough. This can also be used with in conjunction with scaled integers (ex. ±N*0.001). - Downscaling is used when the values of an array are able to fit on an array with smaller type. Therefore an can be downscaled to
INT16or eventINT8. The original array type is preserved and restored at decoding. - Repeated items are also optimized when the values of the array is simply a single value repeated.
- Finally, array portions of similar type are grouped together forming chunks, with a shared optimization applied to them.
Finally, many arrays are repeating objects or other arrays. For example, a big mesh with thousands of faces, might have the same normal vector in all of them. In order to avoid repeating the data all over the file, I am also de-duplicating items that I have encountered before. That said, here is the op-code table for the array:
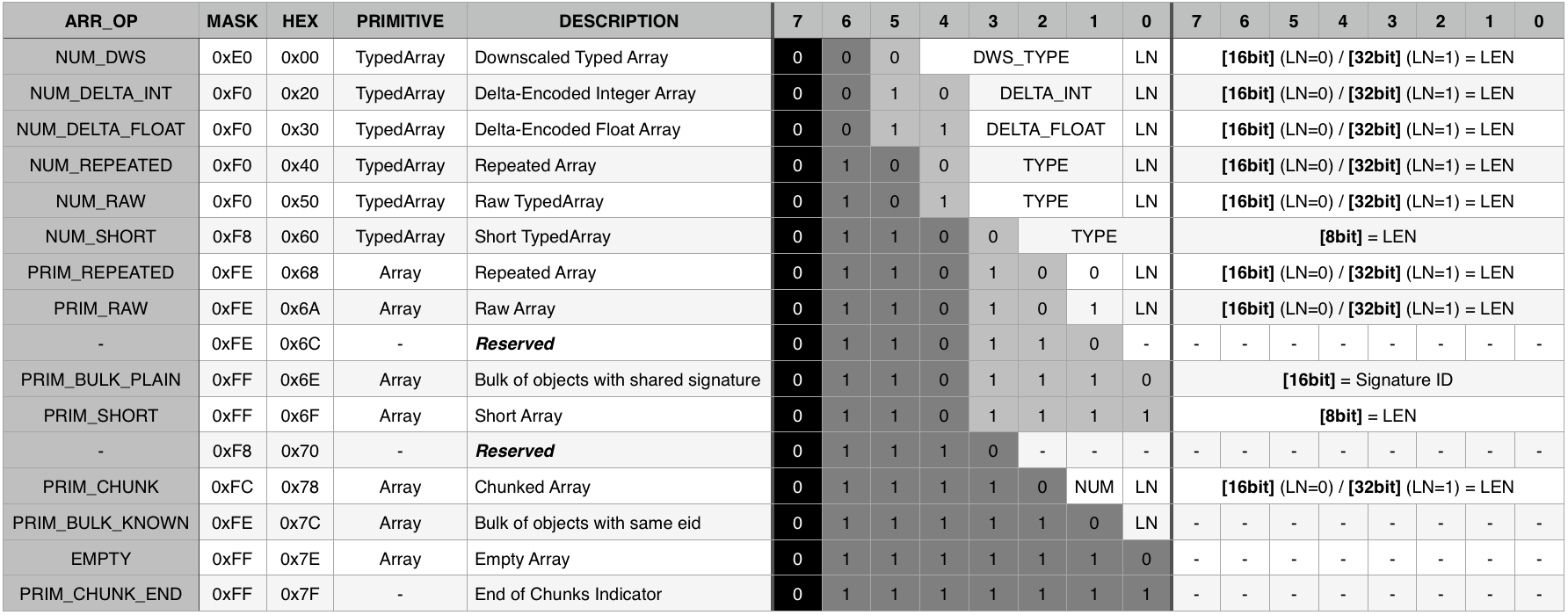
Encoding Objects
Objects were a bit more tricky to store than the rest of the primitives. That's because they usually contain more properties after being instantiated, than the ones needed to construct them. A good example is the THREE.SphereGeometry - or similar geometry generators in three.js. It's constructed with 7 numbers as arguments, but it's possible to create thousands of vertices, stored as geometry properties.
Therefore I decided to be smarter on the way I encode objects, and decided to use a Table of Known Objects, for their encoding. This means that the encoder/decoder shares a table with information about how to construct and how to extract information from a predefined set of objects.
Having this in place, the encoding speed -and more importantly- the resulting size is considerably smaller. Behind the scenes, the object is encoded with it's index on the ToKO and an array with it's properties (further optimized as seen before).
The JBB Compiler
Having my format settled, and having written the first versions of the encoder/decoder script, I started working on the compiler. Since this JBB is a serialization format, the compiler will have to perform the following steps:
- Load the scene and it's resources in memory
- Load all the depending bundles in memory
- Pass the pointer of the data structure(s) that I need to save to the encoder
The encoder will take care of replacing the references to the depending bundles, optimally encode the objects and write the properly aligned jbb file.
I was disappointed by the performance on my earlier versions of the jbb compiler. It took almost 3 minutes to compile a bundle consisting of some UTF8 models and an animated JSON model. The result was two bundles, one for the meshes and one for the textures, totalling 3.1Mb after a gzip compression. That's not much of a difference from the 3.7Mb of the original resources. However the loading time was considerably different!

Performing only 2 requests in the binary bundle version (instead of about 20 in the regular one), the browser loaded the bundle 5 times faster!
The later version of the compiler reduced the compilation speed, by carefully tuning the source to comply with the optimization internals of V8. That's another story that I could share in the future...
Concluding, I would say that this experiment was a success, demonstrating how TypedArrays can be optimally exploited for bundling binary resources for the web. I can never say that this is a perfect replacement for the many solutions already existing in the pipelines of various designers, but I am hoping to provide a new interesting resource to all of you out there. So, I am looking forward to hearing from your experiences with JBB!
Github: https://github.com/wavesoft/jbb